
Summary: NYTimes.com has a new paywall set up that allows you to view the homepage and up to 10 articles per month without pay, with unlimited articles being available if you start paying for it. Here are seven ways to avoid that limit, if you cared do such a thing.
Eight [relatively quick] ways to get past the 10-articles per month limit for New York Times's nytimes.com
BLOT: (22 Apr 2012 - 06:35:34 PM)
Eight [relatively quick] ways to get past the 10-articles per month limit for New York Times's nytimes.com
If you view NYTimes regularly, you have probably noticed that (a) they have started to limit how many pages you can view and, just recently, (b) has moved that count from 20 nytimes.com articles per month down to 10. The cost of a subscription is a little variable (there's a student pricing, for instance), but for casual news browsers, the sort who might read 12 news articles on a website in a month but never more than 13, paying about $15 a month is paying more than $1 per news article, and at costs like that you might as well get your [hopefully non-sucky] local newspaper and avoid a national syndicate. You can also—just for looking-at-adverts, which you also do, though to perhaps a smaller degree, on the post-payment Times site—get a wide range of other news sources so unless you are particularly smitten with the NYTimes.com, your first instinct is to probably to mozy on elsewhere.
As something of a thought experiment, I started going through the steps in my head to figure out ways around this limit. I found several within just minutes and realized that for a company like the New York Times, that needs a site that is accessible from search engines and needs to generate buzz to get casual browsers, there are certain assumptions that have to be in place. What's more, the nature of these expose certain underlying problems and assumptions with the web-at-large. But let me show you what I mean.
1. Multiple Browsers
Practicality (100 point scale): variable, Technical Ease: assuming you know enough to know how to install more than the default browser, 90. If not, who knows?
The Gist? Have multiple browsers installed on your computer: Chrome, Firefox, Safari, Internet Explorer, Opera, etc. Unless my underlying assumptions are mistaken, then the website tracks the user with browser-specific cookies. This means that dividing your surfing time up between multiple browsers will double, triple, etc your number of articles to read. Likewise, if you have access to multiple computers—home desktop, laptop, mobile device, work desktop, library lab computers—you can again extend your limit. Though some public access terminals are going to count any user's use against the limit so you might find that already burned up.
Added Value? Various browsers tend to have varying skills at rendering certain elements, so it can be useful to have a grasp of which browser is better at what.
The Downside? Kind of obvious, but you have to try and juggle multiple resources and opening up another browser to read an article can be bothersome (if only mildly so). Also, copy-and-paste the URL directly (up to the .html bit) or you will end up burning up your article limit just getting back to where you were.
Chance they could patch this hole? Mild, unless they want to force everyone to sign in to view any articles. Which is sort the breaking point of most of these techniques.
2. Google (et al) Search - "site:nytimes.com"
Practicality presumed about 80, Technical Ease: eh, how about from 60-90?
The Gist? If you search Google with something like the name of the article in quotes and then include "site:nytimes.com", you should be able to get the article back as a search result, which will not count against you, (well, it counts but you can go past 10). Example, with a made up article name, '"Obama says jobs on the rise" site:nytimes.com' (that would be without the single quotes).
Added Value? Learning how to "site:" search is always, ALWAYS, a good thing.
The Downside? (1) No clue how long until articles actually show up, (2) no clue at how many false hits you'll get, (3) can get kind of tedious. You are essentially trust in Google/Bing/etc to return the article you want, as opposed to other articles with possibly the same name and/or blog posts about the article that don't have direct links back to the article.
Chance they could patch this hole? They could do something like IP tracking, or require a log on, or disallow search results except for so many times, and so forth.
3. Private Browsing
Practicality: 75, Technical Ease: 75.
The Gist? In Firefox, it is called Private Browsing. In Chrome, it is opening an Incognito Window. Others probably have something similar. You open a browser session where your activity will not be retained and your prior activity will be considered hush-hush. By doing this, cookies and history will be deleted when you stop that private/incognito session and so the website will have to assume that you are af fresh visitor.
Added Value? Private/Incognito browsing protects your identity and prevents tracking and so is not a bad habit to cultivate, especially on public computers.
The Downside? First off, it is not going to remember your session and so if you are of the sort that loves to look at your history rather than take notes or make bookmarks, you will not find what you did. Also, different browsers handle the break-out session differently, not to mention that completely trusting the browser and/or website to really protect your identity is always dangerous. Finally, some people have trouble keeping track of tabbed browsing, so keeping track of multiple windows with varying privacy levels might be beyond them to fully juggle. Oh, and a bonus "finally", if you are prone to viewing more than 10 articles at a time, just one private session might not be enough.
Chance they could patch this hole? IP tracking would do it, to a degree (see multiple computers, though), and there are other ways to script server-side handling of perpetual cookie-less accounts (three link clicks with no cookies? assume the worst!).
4. Twitter (see also: Facebook, G+)
Practicality: 60, Technical Ease: 85.
The Gist? Aware of the vital shifts in social media and how much it impacts any online business, NYTimes.com allows you to keep reading if you a follow a link from a blog, Twitter, etc etc (see short FAQ for citation). Therefore, to read links all you first need to do is have some sort of social media set up and then just share it. Follow the link and bam! These count against your 10-per-month, but the difference is that you are not cut off.
Added Value? Most of the added value is for NYTimes.com, actually, since it will share their materials and drive up their overall readership. You also get the bonus benefit of looking like the kind of well-informed person who cares a lot about the news.
The Downside? Well, you have to share all the articles you want to read, and there are bound to be some that you might be a bit nervous about sharing, especially in an Everyone-You-Know environment like Facebook ("I swear, Mom, I only wanted to read that article on breast-feeding fetishism from an anthropological perspective!"). Also, if you read a lot of news it is going to make you look like a spamming dick, not to mention that there is still the idea that links you share are things of which you approve and of which you want to get out there, which is generally at odds with you posting the link just to read it.
Chance they could patch this hole? Low, since they want the buzz. There is a bigger chance that they might change the setting to only give people from social sites something of a short-view for the article with sign-in and or cookies required to get the longer.
5. Google Tasks, Email, HTML jiggery-pokery, etc
Practicality: variable, Technical Ease: variable.
The Gist? The nature of the beast basically means that NYTimes is going to allow off-site links (links anywhere but on nytimes.com) to count against you, but to still go through. This means that techniques like emailing yourself an article, adding a link to a Google Task list, and sending yourself an article through a chat (yes, with yourself) should work. What's more, the sky is the limit with this one since there could be any number of methods to scrape links and repost them. How about a script that wgets the homepage and then uploads all the links and text to a page on a private site? Or a Python script where you can save the links you want to visit in a text file and then run it to spit out an html file you can use to follow through, possibly to a protected blog post?Maybe the wget emails you all the big links on the front page? Have fun tinkering.
Added Value? This one has the major advantage of the previous that it doesn't require you having to fling links into the wild (i.e. Twitter, Facebook, G+, etc) in order to see them [though one could imagine a person making a private, no-one-but-themselves Twitter feed to also avoid this], but then it ranges from fairly simply to fairly difficult to set up. However, difficulties of this sort often require learning valuable life skills to overcome, so it might be thought of as training that could later end up on a resume.
The Downside? Link-at-a-time methods are still tedious. And more advanced versions might be wrecked by a style update to nytimes.com.
Chance they could patch this hole? Most of the previous potential patches are relevant here. Added issue could be if nytimes started allowing preferred domains for proper off-site links and ignored others.
6. Delete all cookies upon close
Practicality: variable [see Downsides], Technical Ease: 70.
The Gist? Tell your browser to delete all cookies (and/or all private data) upon each close. Each time you re-open it, it will seem to be a "fresh" browser and therefore sites that count visits by cookies and such private-data will be unable to keep accurate track of overall usage.
Added Value? If you want to be paranoid, may not be a bad habit to get into. This stops longer reaching data tracking from happening, and can help to prevent sites that do things like use cookies to track your activity on other sites [*cough* Facebook *cough*] from doing that, too, though preventing all cookies is probably better for the latter.
The Downside? You'll have to re-login to everything every time you use the web. Some sites also use cookies to have things like a persistent shopping cart and turning on the option to delete browser history guarantees that you'll have to remember what you have and haven't read, since it won't leave an easily searchable record. If you look at more than 10 articles at a go, you'll have to close and reopen your browser.
Chance they could patch this hole? The standards of IP tracking, requiring log-in, et al, apply.
7. Delete/Block Specifically NYTimes.com Cookies
Last time I checked, NYTimes.com now DOES require cookies to be unblocked before you can enter. You can still delete upon close, but you will need to have them enabled while browsing. This means the most you can browse per one session is 10 (then you have to close and restart) but it is still doable, the practicality has been changed to reflect, though.
Practicality: 85, Technical Ease: 60.
The Gist? Browsers allow you to specify exceptions to overall cookie-storage policies. By disallowing ALL third party cookies, and then blocking cookies specifically from nytimes.com, and deleting the ones that have already built up, the site will not able to keep track of how many sites you have seen. One variation would involve not blocking nytimes.com cookies, but going in and searching them and deleting them ever so often as needed.
Added Value? You don't have to worry about logging into all of your other sites or learn how to manage multiple privacy settings at the same time. What's more, you can view more than 10 pages at a time. Of all the tricks in this list, This one is right up there with learning the ins-and-outs of private browsing for practical and relatively easy technical tricks for safer browsing. Dig around in the options until you find the button that shows you how to view cookies and look at all the data websites have stored on your computer, and then using a few searches find out how few of them are actually for sites that you figure would need cookies for your benefit. You can probably find a few that you aren't comfortable with having cookies. Al in all, learning how to manage this on a site-by-site sort of basis is just smart browsing.
The Downside? Essentially none. You aren't blocking other sites from leaving cookies. Until nytimes.com is redesigned to require cookies to click a link from nytimes, you won't find this too bad.
Chance they could patch this hole? If they require a log-in, use IP-tracking, or require cookies to be put upon clicking a nytimes.com link from nytimes.com, then it could patch it up. Outside of that, this one is pretty safe.
8. Pay for it
Practicality: variable, but let's assume 50+, Technical Ease: probably at least 90.
The Gist? It's a website that has a paywall to insure the content gets valued without devolving into a blinking ring of advertisements somewhat more garish than Las Vegas on a bad day. Pay for said service and enjoy the benefits of being a customer (like having to read articles without going through crazy schemes and loops).
Added Value? The content gets paid for and, if you use the site a whole lot, then you get the satisfaction of knowing you support something that is useful to you. What's more, as an actual paying customer, when you do things like scream at them for charging you $15 a month and still make you look at advertisements, it means something.
The Downside? You end up having to pay for it. And while it is not a whole lot of money, relatively, it still is approximately $15 more than any other news-site you might care to read. Also, you end up supporting kind of strange set-ups that lead to all the crazy scenarios that make #'s 1-7 possible. And that's probably a bad thing.
Chance they could patch this hole? Since patching it means getting rid of the paywall, possibly the smallest chance of all.
In conclusion...
If you use nytimes.com sparingly, then none of these are necessary. If you use it a lot, then #8 is your best option [and welcome to the paying-for-things club!], but for those in the middle or with any of a number of other reasons, I'd recommend #7. Learning a little bit more about the backend of your browser is never a bad thing, it's a good lesson about computer safety, and it doesn't require link-at-a-time methods or strange and artificial methods to manage which browser you view which number of links on when.
Screenshots and such, for those that might need them
Adding a website to block/allow as a specific exception for cookie handling on Firefox

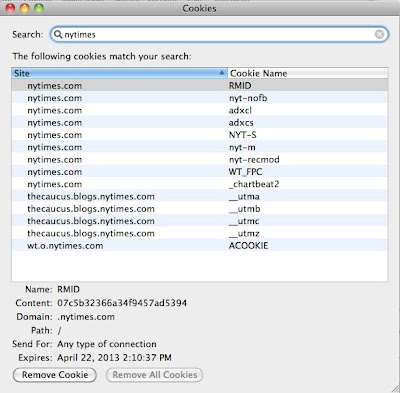
Cookies added after only looking at 2-3 pages on nytimes.com
Blocking a specific website from adding cookies on Chrome

Clearing private data upon close in Chrome
![]()
OTHER BLOTS THIS MONTH: April 2012
dickens of a blog




Written by Doug Bolden
For those wishing to get in touch, you can contact me in a number of ways

This work is licensed under a Creative Commons Attribution-ShareAlike 3.0 Unported License.
The longer, fuller version of this text can be found on my FAQ: "Can I Use Something I Found on the Site?".
"The hidden is greater than the seen."